The git staging area
So far, we have been mostly interested in git commits trees, and not so much about how those commits were created.
Time to fill that gap.
Different areas in git
When working with git, there are three different areas to consider.
the git repository
That’s where git stores all the commits and their associated metadata information.
All those files are stored in the .git directory.
the working directory
This directory is the developer’s workspace on her computer’s filesystem. The files in that directory are regular files which constitute the content of the project.
the staging area
Git’s primary responsibility is to allow the transition of data between the working directory and the git repository:
- when a user clones a repository or checks out a branch, git must convert a set of commits in plain old files in the working directory
- when a user wants to commit her work, git must convert data from the working directory into commits in the git repository
The staging area is the buffer between the git repository and the working directory.
In terms of shape, the staging area is very much like a commit. It contains information about files and directories, and like commits, the staging area refers to blobs and trees for the git database and not files from the working directory.
The staging area is the mechanism which allows the developer to build her next commit.
The content of the staging area is in a single file: .git/index
Exploration time
Let’s start from an empty repository and create our first file.
$ date > A.txt$ git statusOn branch masterNo commits yetUntracked files: (use \"git add <file>...\" to include in what will be committed) A.txtnothing added to commit but untracked files present (use \"git add\" to track)At this stage, the staging area doesn’t even exist, no commit has been created and there is a file A.txt in your working directory.
The first step to prepare a commit is to do a git add:
$ git add A.txtThis will create the staging area (.git/index file) and you can see it’s content with the git ls-files command:
$ git ls-files --stage100644 0bca567a0af4853378234308e2a0b26a2f0abe54 0 A.txtBut no commits has been created yet:
$ git statusOn branch masterNo commits yetChanges to be committed: (use \"git rm --cached <file>...\" to unstage) new file: A.txtTime to create our first commit:
$ git commit -m 'first file'[master (root-commit) b893588] first file 1 file changed, 1 insertion(+) create mode 100644 A.txtThis time we have out first commit:
 This does not change the content of our staging area:
This does not change the content of our staging area:
$ git ls-files --stage100644 0bca567a0af4853378234308e2a0b26a2f0abe54 0 A.txtIn a clean situation, the staging area is a copy of our current commit (HEAD).
Let’s create another file and git add it: this will add that file to our staging area:
$ date > B.txt$ git add B.txt$ git ls-files --stage100644 0bca567a0af4853378234308e2a0b26a2f0abe54 0 A.txt100644 d5edb504d978f963a5cc6f2adaf8acf7014e2f3e 0 B.txtThis staging area allows git to provide a status about the intent of the developer:
$ git statusOn branch masterChanges to be committed: (use \"git reset HEAD <file>...\" to unstage) new file: B.txtAt this stage, we can modify B.txt right?
$ date >> B.txtThe git status result is interesting after that change:
$ git statusOn branch masterChanges to be committed: (use \"git reset HEAD <file>...\" to unstage) new file: B.txtChanges not staged for commit: (use \"git add <file>...\" to update what will be committed) (use \"git checkout -- <file>...\" to discard changes in working directory) modified: B.txtThe file B.txt appears in 2 sections of the status description:
- because this file is in the staging area, this file is marked as a new file to be committed
- but its content in the working directory is different from what is in the staging area, so this file is also marked as a non staged file
If we git add that file:
$ git add B.txtThe staging area is now:
$ git ls-files --stage100644 0bca567a0af4853378234308e2a0b26a2f0abe54 0 A.txt100644 169638e3aaacc9efbd9b5664cb718292271934f1 0 B.txtSame 2 files as before but the astute reader will notice that the sha1 for B.txt is different (is now169638 and was d5edb5 before)
That is the file which will be commited now:
$ git commit -m 'second file'[master 495430b] second file 1 file changed, 2 insertions(+) create mode 100644 B.txt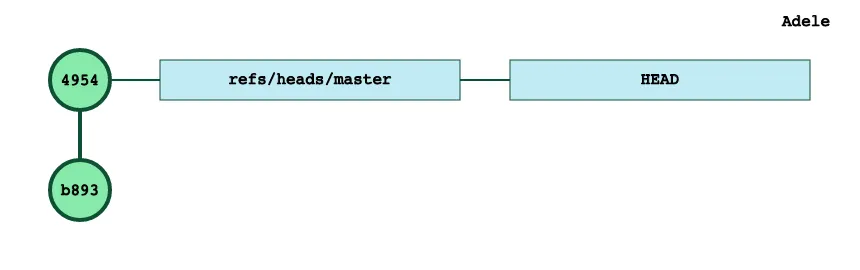 We can also delete this file
We can also delete this file
$ rm B.txt$ git statusOn branch masterChanges not staged for commit: (use \"git add/rm <file>...\" to update what will be committed) (use \"git checkout -- <file>...\" to discard changes in working directory) deleted: B.txtno changes added to commit (use \"git add\" and/or \"git commit -a\")The staging area has not changed, so git can report that there is an uncommited change (the deletion of B.txt).
Thanks to the staging area, we can revive that file:
$ git checkout B.txt$ git statusOn branch masternothing to commit, working tree cleanBut we could also move forward with the deletion:
$ rm B.txt$ git rm B.txt # git add B.txt would work too!$ git statusOn branch masterChanges to be committed: (use \"git reset HEAD <file>...\" to unstage) deleted: B.txtand now the staging area is back to 1 file and we can update our repository accordingly:
$ git ls-files --stage100644 0bca567a0af4853378234308e2a0b26a2f0abe54 0 A.txt$ git commit -m 'remove B.txt'[master 45d0ee3] remove B.txt 1 file changed, 2 deletions-) delete mode 100644 B.tx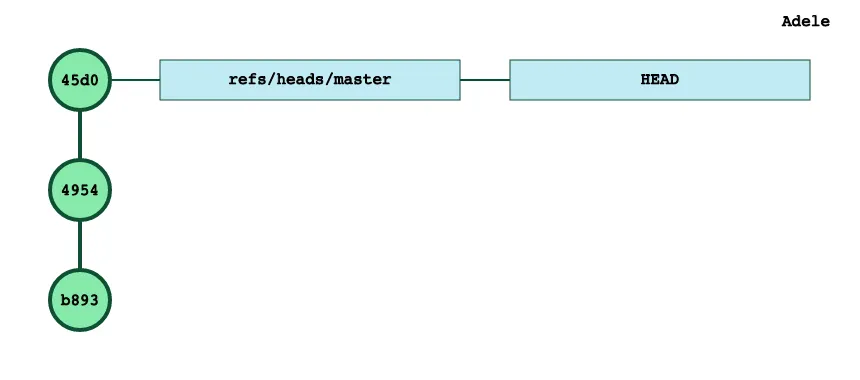 Finally, let’s suppose that we have a branch branch01 with 2 commits :
Finally, let’s suppose that we have a branch branch01 with 2 commits :
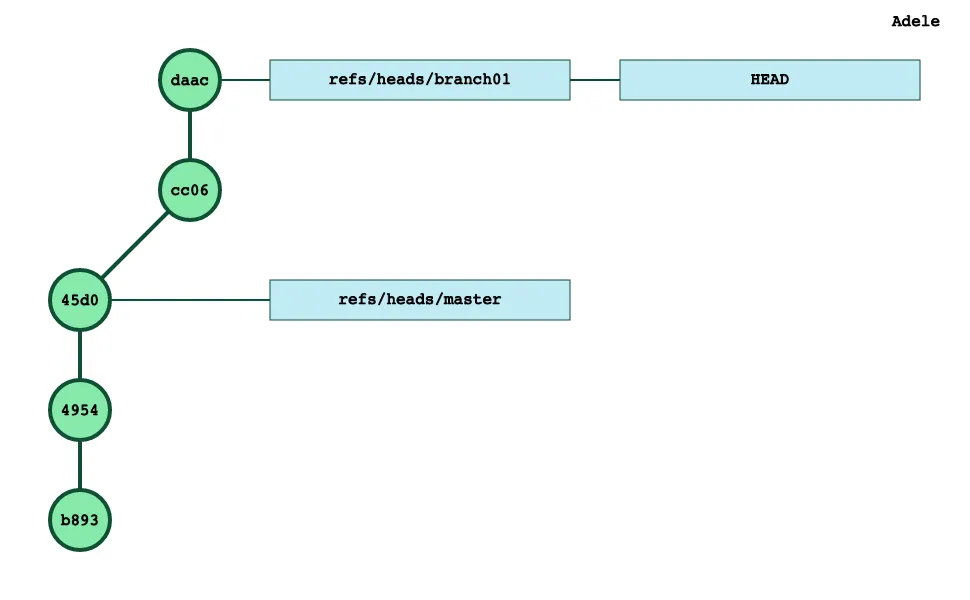 As usual, the staging area is a copy of our current HEAD commit:
As usual, the staging area is a copy of our current HEAD commit:
$ git ls-files --stage100644 0bca567a0af4853378234308e2a0b26a2f0abe54 0 A.txt100644 533f481382e4855bdd7a81aa54fb9737e49de055 0 C.txt100644 f6dff21336221ade8dc313a4f018afab6dd43146 0 D.txtWe can vizualize the fact that the staging area is actually some sort of a copy of the HEAD commit (daac) by listing the content of that commit:
$ git cat-file -p daactree 2db45b3c2cb2c9ee7e9129c64f47f135902193d7parent cc063e668d960cc9b553e5f1229a46df6287f594author Pierre Carion <pcarion@gmail.com> 1572196890 -0700committer Pierre Carion <pcarion@gmail.com> 1572196890 -0700add D.txtThe key element here is the tree reference (2db45) which is a description of the tree associated to that commit.
We can also explore the content of that tree:
$ git cat-file -p 2db45b3c2cb2c9ee7e9129c64f47f135902193d7100644 blob 0bca567a0af4853378234308e2a0b26a2f0abe54 A.txt100644 blob 533f481382e4855bdd7a81aa54fb9737e49de055 C.txt100644 blob f6dff21336221ade8dc313a4f018afab6dd43146 D.txtWhich is exactly the content of our staging area:
git ls-files --stage100644 0bca567a0af4853378234308e2a0b26a2f0abe54 0 A.txt100644 533f481382e4855bdd7a81aa54fb9737e49de055 0 C.txt100644 f6dff21336221ade8dc313a4f018afab6dd43146 0 D.txtAnd each time we switch branch, not only the HEAD reference will be updated to match the new current branch, but the staging area will be updated to match also the content of the new top commit:
$ git checkout masterSwitched to branch 'master'$ git ls-files --stage100644 0bca567a0af4853378234308e2a0b26a2f0abe54 0 A.txt
